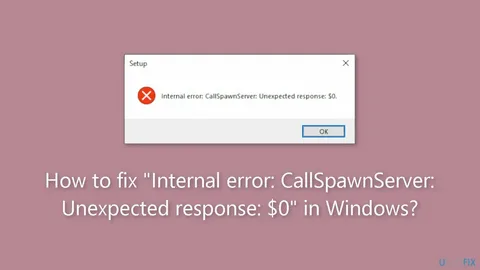
How to Get Images From a Dead HTML?
Web Pages often go on the internet, leaving behind the leftover information. Suppose you find yourself needing images from an archived or inactive HTML page. This article will walk you through How to Get Images From a Dead HTML?
Critical Points
1 – The most important thing you need to ensure is whether the image exists in the same place you think or not. To find an image, you need to open an exact file; in all this extraction, you may accidentally move or delete your essential files.
2- The file name must be exactly what you typed in the code, as a little spelling mistake or a typo error can be overlooked by you, but for a computer, spelling differences will be considered another file.
Restore images from dead HTML
1- Inspect Image URLs: Right-click on the webpage and select “Inspect.” Navigate to the “Network” tab and refresh the page. Look for resource entries labeled “Img” or “Image.” You can often find direct image URLs here.
2- Explore Browser Cache: Check your browser’s cache for stored images. Browsers often keep copies of recently visited images.
3- Use Archieve.org: visit the archieve.org and enter the URL of the inactive page. Explore the archived snapshots and download images directly from the captured versions.
4- Save Page for Offline Browsing: save the entire webpage using browser tools like “Save Page As.” Extract images from the saved folder
5- HTML Download: download the HTML of the inactive page. Use tools like wget or curl. Once you have the HTML file, employ image extraction tools to retrieve images referenced in the HTML code.
FAQs
Q1: Can I legally use images obtained from inactive pages?
A: It’s crucial to respect copyright laws. If the images are under copyright, obtaining permission or ensuring fair use is essential before using them.
Q2: What if the images are not directly visible in the HTML code?
A: Some websites use complex structures or scripts to load images. In such cases, consider using web scraping tools or seek professional assistance.
Q3: Are there any browser extensions for image extraction?
A: Yes, several browser extensions, such as “Image Downloader” or “Save Images,” simplify the process of bulk image downloading from web pages.
Q4: Is it ethical to retrieve images from inactive pages?
A: Ethics play a crucial role. Retrieval may be ethical if the website’s terms of service allow it or if the content is in the public domain. Otherwise, consider seeking permission.
Q5: What if the archived versions don’t have the desired images?
A: Retrieving the images may prove challenging if the pictures were not archived and the original website is inactive. Exploring alternative sources might be necessary.
Q6: Can I use online HTML for image converters?
A: It’s recommended to use a combination of methods for comprehensive retrieval.
In conclusion, always respect intellectual property rights and use retrieved content ethically; it must be the foremost responsibility. Dead HTML is like a graveyard, so Happy Hunting in a Digital Graveyard.